
Red Hat announced jointly-engineered, integrated and supported images for Red Hat Enterprise Linux across Amazon Web Services (AWS), Google Cloud and Microsoft Azure.
Will the Real "Modern Data Stack" Please Stand Up?
November 08, 2021
Over the past few years the "modern data stack” has entered the vernacular of the data world, describing a standardized, cloud-based data and analytics environment built around some classic technologies. In its simplest form, this looks like:
1. A data pipeline (ETL or ELT) moving data from its source into an analytics-focused environment
2. A target data warehouse or data lake
3. An analytics tool for creating business value out of the data
This technology stack is based on the fundamental idea that data must be moved away into a centralized location in order to gain value from it. One thing to note, however, is that what we call the "modern data stack” is essentially a re-envisioned cloud-and-SaaS version of the "legacy data stack'' with better analytics tools. What started out as a stack with a database + enterprise ETL tool + analytics-focused storage + reporting system became a modern version of the same functional process.
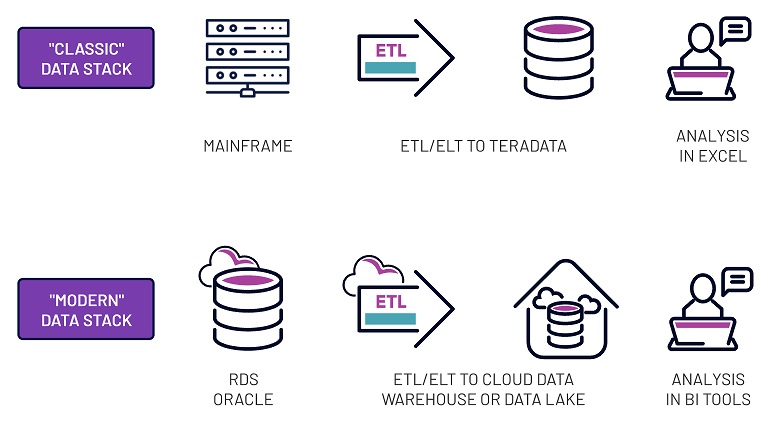
Despite new cloud-based and SaaS tools, the paradigm remains the same
A Flawed Paradigm
The "modern data stack” is a reimagining of the legacy data flow with better tools. The original stack was largely driven by hardware limitations: production transactional systems simply weren't designed to support an analytics workload. By moving the data from the production system into a replicated analytics-focused environment, you can tailor your data for reporting, visualizations, modeling, etc. However, there are still some pretty serious flaws in both versions:
By moving data away from the source, there is an inherent latency introduced along with complex and fragile data pipelines. Getting back to "real time analytics” can be incredibly challenging and involve large data engineering efforts.
While modern cloud-based data warehouses and data lakes allow for the separation of storage and compute resources and both horizontal and vertical scaling, the true separation of these resources (meaning private storage and shared compute) remains a challenge.
Complex enterprise environments with many operational systems struggle with the idea of bringing all data together in a cloud data warehouse with a common data model - in practice, this rarely works.
The recent focus on tools, rather than functionality, ultimately leads to vendor lock-in and blocks optionality. The bottom line is that there is still a large disconnect between the source data and the final business value.
In thinking about these flaws inherent in the modern data stack, we've started to instead wonder: What is a truly modern data stack?
Imagine you're dropped into a company and asked to build a system to easily access data for the purpose of deriving business value. Your employees are data literate - they understand SQL and want to use that and maybe a visualization tool like Tableau to answer business questions using data. You've got today's modern infrastructure, your production transactional databases are all in the cloud, and you want to separate storage and compute. You're not hardware-bound at all. What would you build?
Introducing the Four S's
Let's focus on what the business user wants:

The 4 Ss of data: speed, scalability, simplicity, and SQL
In the end, these are the goals, and you want to focus your architecture and data ecosystem on these principals. If you can achieve each of these "four S's” with your new data system, you'll be a hero!
Building something truly modern
To build a system that meets your goals while focusing on simplicity, start with a product that allows you to run SQL directly on your source data, wherever it lives, without the need for a large effort around data infrastructure. Then add in the analytics layer with a visualization tool, machine learning, etc. This actually isn't drastically different from the modern data stack, but the distance between the data and the value is shortened; in a complex and scaling organization, this efficiency gain can be significant.
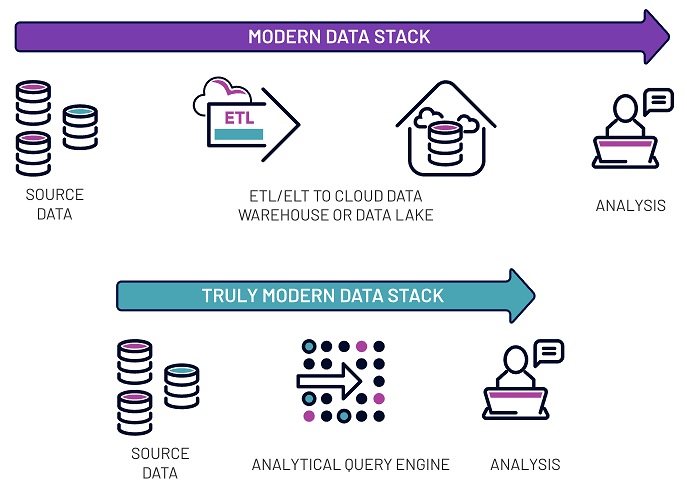
The truly modern data stack focuses on the four Ss, reduces latency and complexity, and is vendor-agnostic, ultimately shortening the path between the data and the business value derived from it
Benefits of this simpler stack include reduced batch processing, and the capability to use live or cached source data will reduce latency. Governance including data lineage will also be more transparent with fewer intermediary tools and datastores. The smaller number of tools and storage requirements, not to mention the true separation of storage and compute resources, also lends itself to a streamlined and more cost-effective data ecosystem.
Enter Data Mesh
As complexity and the need for data maturity grows at an organization, often an enterprise will have many different domains with their own unique data ecosystems and analyses. However, when data is a primary factor in business strategy, it's the analysis of data across the organization that brings true exponential power. At this point, companies need to think about a global data strategy, and proactively treat data as a first-class business product, rather than a happy afterthought. The business goal is to embrace agility in data in the face of complexity, and accelerate the time-to-value for data.
Organizationally and architecturally, Data Mesh marries the ideas of a truly modern data stack with the concept of data as a top-tier product. Data producers treat data consumers as a first-class stakeholder of their work, and the consolidation of the technologies for data consumption brings about a revolutionary simplicity of the data and analytics model at scale. With its guiding tenets, Data Mesh is firmly cementing its place as the future of the business data ecosystem:
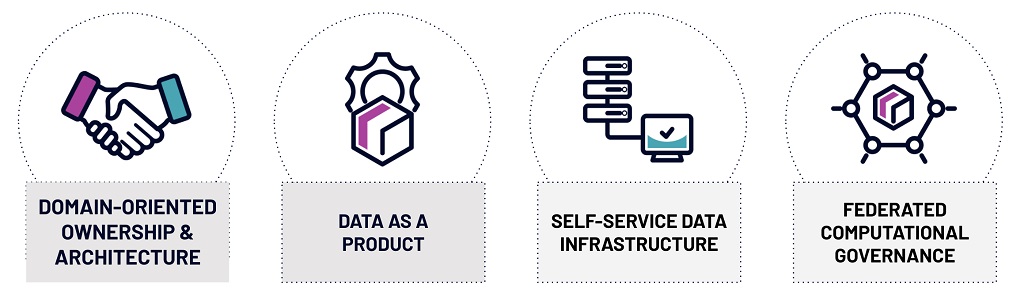
Core principles of Data Mesh
While Data Mesh defines a global socio-technical architecture for an enterprise's overall data strategy, there is a place for the "truly modern data stack” within this architecture, as each domain will be required to pull data from the operational plane, transform it for analytics, and provide access in the analytical plane. The transitioning and transformation of that data is itself a data stack, driving the concept of data as a first-class product of a domain at the same level of importance as code. This is a key driver of Data Mesh and an incredibly important concept for the business as it cements the idea of data as a primary concern for both the business and the domain. The "truly modern data stack” can be considered a key piece of the data infrastructure for domains to provide data products in the analytical plane; global data governance marries together these domains' stacks through access control.
What's Next?
The so-called "modern data stack” has its roots in outdated architectures built for antiquated hardware, and stands to be reimagined. The combination of the "four S's” and the four driving tenets of the Data Mesh provides a framework for simplicity and resiliency within a data ecosystem, as well as providing optionality across domains. As many organizations mature their data and analytics strategy, considering all of the data stacks within the company as a whole is an important step.
The goal is to architect a solution that can be used both within the domains as a data product creation technology, and across the domains as an analytical query engine, to create a data ecosystem that combines the "truly modern data stack” with the Data Mesh. A solution that provides a self-service data infrastructure along the one defined as a pillar of Data Mesh can be used cross-functionally in an organization. With a flexible data environment to create data products, query across data products, and even create additional data products from existing data products - the possibility of mirroring a more complex ecosystem is straightforward within this type of product ecosystem.
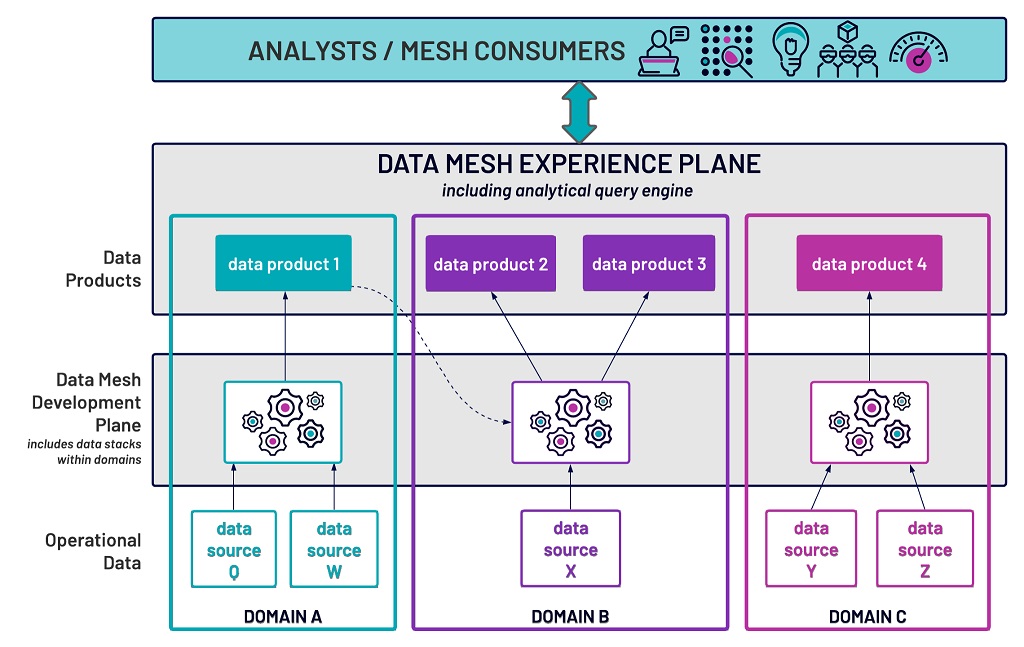
A Data Mesh incorporating the "truly modern data stack” can raise the bar, streamlining the path between data producers and business value. Providing direct SQL access to a wide array of data sources is key to unlocking the power of data to drive business strategy.
Industry News
May 21, 2025
Komodor announced the integration of the Komodor platform with Internal Developer Portals (IDPs), starting with built-in support for Backstage and Port.
May 21, 2025
Operant AI announced Woodpecker, an open-source, automated red teaming engine, that will make advanced security testing accessible to organizations of all sizes.
May 21, 2025
As part of Summer '25 Edition, Shopify is rolling out new tools and features designed specifically for developers.
May 21, 2025
Lenses.io announced the release of a suite of AI agents that can radically improve developer productivity.
May 20, 2025
Google unveiled a significant wave of advancements designed to supercharge how developers build and scale AI applications – from early-stage experimentation right through to large-scale deployment.
May 20, 2025
Red Hat announced Red Hat Advanced Developer Suite, a new addition to Red Hat OpenShift, the hybrid cloud application platform powered by Kubernetes, designed to improve developer productivity and application security with enhancements to speed the adoption of Red Hat AI technologies.
May 20, 2025
Perforce Software announced Perforce Intelligence, a blueprint to embed AI across its product lines and connect its AI with platforms and tools across the DevOps lifecycle.
May 20, 2025
CloudBees announced CloudBees Unify, a strategic leap forward in how enterprises manage software delivery at scale, shifting from offering standalone DevOps tools to delivering a comprehensive, modular solution for today’s most complex, hybrid software environments.
May 20, 2025
Azul and JetBrains announced a strategic technical collaboration to enhance the runtime performance and scalability of web and server-side Kotlin applications.
May 19, 2025
Docker, Inc.® announced Docker Hardened Images (DHI), a curated catalog of security-hardened, enterprise-grade container images designed to meet today’s toughest software supply chain challenges.
May 19, 2025
GitHub announced that GitHub Copilot now includes an asynchronous coding agent, embedded directly in GitHub and accessible from VS Code—creating a powerful Agentic DevOps loop across coding environments.
May 19, 2025
Red Hat announced its integration with the newly announced NVIDIA Enterprise AI Factory validated design, helping to power a new wave of agentic AI innovation.
May 19, 2025
JFrog announced the integration of its foundational DevSecOps tools with the NVIDIA Enterprise AI Factory validated design.
May 15, 2025
GitLab announced the launch of GitLab 18, including AI capabilities natively integrated into the platform and major new innovations across core DevOps, and security and compliance workflows that are available now, with further enhancements planned throughout the year.

