
SmartBear announced a new version of its API design and documentation tool, SwaggerHub, integrating Stoplight’s API open source tools.
What Netflix Teaches Us About DevOps Culture
August 30, 2021
Netflix didn't set out to create a "DevOps culture." They didn't follow a set of predefined rules. They didn't have endless strategy meetings. They didn't have to hire DevOps consultants.
Instead, they developed a DevOps culture organically. And it all started with the worst outage in their history.

(image by Thibault Penin)
Their then Head of IT Operations, Mike Osier, recalled how the 2008 disaster began: "On Monday, 8/11, our monitors flagged a database corruption event in our shipping system. Over the course of the day, we began experiencing similar problems in peripheral databases until our shipping system went down."
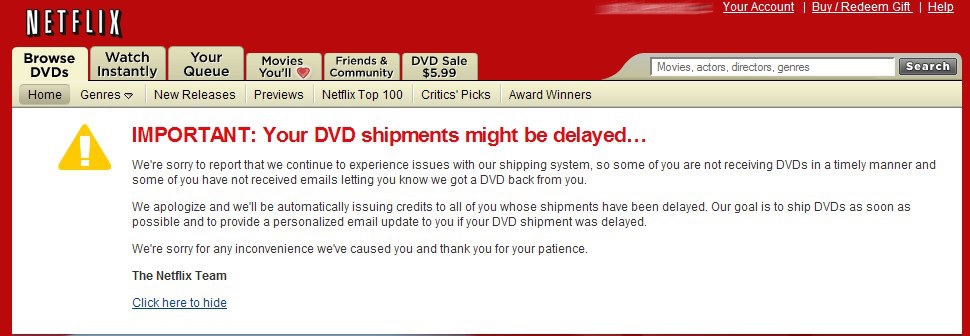
Netflix was, to this point, still largely reliant on physical DVD sales. A takedown of all 55 of their distribution centers meant that no small portion of their entire business was frozen.
It was going to be a long night.
The following day, the company still couldn't ship DVDs. On Wednesday, it was the same. And Thursday.
(image via CNET)
It was the event that changed everything. "That is when we realized," wrote their VP of Cloud Computing, "that we had to move [. . .] in the cloud."
Except it wasn't a sudden realization, or a snap decision. In the "Towering Inferno" — a rather ordinary top floor conference room in their Los Gatos, CA headquarters — engineers and executives got together and hashed out a plan. It took several meetings, and long hours of discussion. The goal was to never let something like what they just experienced happen again.
But how? This was 2008, remember, and the cloud was still very new. Most people didn't even know it existed. Amazon — Netflix's chosen provider — had only been offering their AWS service for a couple of years. There was no rulebook on how to migrate; how to implement.
And it wasn't just a technical challenge, either: it was philosophical, cultural. Netflix stood at a crossroads of what kind of company they were going to be in the future.
Down one path, they'd continue, broadly speaking, as they were before. They could do a simple "lift-and-shift": pick up the Netflix app, dump it onto the cloud, and fix whatever was necessary to make it fit. Past that, everything would remain as usual. Simple. Easy.
They chose the other path.
"We thought: ‘Let's rethink this completely, go back to ‘first principles'," recalled Neil Hunt, Chief Product Officer at the time. "First principles" meant fundamentally rebuilding their application — how it worked, and how they worked on it — from the ground up. In so doing, they stumbled upon what we as a DevOps consulting company frequently champion as a "DevOps culture."
DevOps can take many forms, but, in any case, it requires:
■ Bringing development and IT operations teams together (obviously)
■ Systematizing the software release cycle: e.g. who does what, in what order, how, etc…
■ Automation (where possible)
The goals of DevOps are to:
■ Save time and resources
■ Release software faster
■ Maintain a high quality standard
■ Achieve the goals of the business

(The "Towering Inferno"; image via Business Insider)
DevOps culture is much broader than that, though. It's about building an environment that supports collaboration — getting everyone on board with one, shared mission. It's about being Agile. Sometimes, like in the case of Netflix, it involves making up your own rules, or breaking existing ones.
The first step in their transformation was to move from a monolith to a microservices architecture. With microservices, developers could operate independently. And, with CI/CD pipelines, they could work continuously to apply changes to the app without any need for wholesale updates.
Still, CI/CD isn't enough on its own. Proper DevOps requires strict, systematic quality control in order to ensure that every new release works and, importantly, works within the whole. So, as their CPO, told Increment Magazine, they didn't just build their new app on the cloud, or build it on-prem and then move it to the cloud:
"We would run our existing infrastructure, and side by side run our AWS infrastructure, and migrate one piece at a time, from one system to another."
Two apps, side by side, being constantly and rigorously tested in order to ensure quality.
And yet it wasn't enough. After all, you can test software all you'd like, but there's no way to cover against every potential failure. The new cloud app was resilient to the kind of error that embarrassed the company in 2008, but what about other unforeseen errors that could cause equivalent or even worse damage? This was the fear that spawned the "Simian Army."
The Simian Army embodies many of the core principles of DevOps: automation, quality assurance, thinking of what the business needs and then working backwards. And yet, it's something few other companies would ever consider — because it's essentially a squad of software designed to break things. The first recruit in this army was Chaos Monkey, whose name, according to Netflix:
"...comes from the idea of unleashing a wild monkey with a weapon in your data center (or cloud region) to randomly shoot down instances and chew through cables -- all the while we continue serving our customers without interruption."
We're talking about a set of tools designed to run 24/7, in all environments, causing chaos by randomly triggering errors and shutdowns. Chaos Monkey randomly disables common production instances. Chaos Gorilla simulates what would happen if an entire region of the AWS cloud went completely offline. And there are half a dozen more. The goal, ultimately, is to prepare for every possibility by actively causing it.
"So next time an instance fails at 3 am on a Sunday, we won't even notice."
This wasn't just a hypothetical. On April 21st, 2011, one of Amazon's premier data centers — US-East-1 — cut out, bringing a number of popular websites down with it. On the 25th of September, 2014, a full 10% of Amazon's web servers worldwide shut down for a maintenance update. In neither case did anybody streaming Breaking Bad, or Orange is the New Black, notice a difference, because, as Netflix pointed out, the "systems are designed explicitly for these sorts of failures."
Not every company can pull off what Netflix did in terms of DevOps. Some have failed, "because they simply don't have the engineering muscle that Netflix does. Even though they may want to deliver faster and more efficiently and are even OK with taking on a little more risk, they can't. They need the team to make it happen." Or the help of a DevOps advisory services company.
Either way, the lesson is the same: DevOps isn't about following strict rules. It's about creating a culture. Netflix created their own rules, before there were rules, and then they broke some old ones. But they created a culture where everyone had a seat in the conference room--where developers could build well, test often, and edit their work, and operations had the backing they needed to ensure top quality.
The next time you stream your favorite show in full HD, uninterrupted, thank DevOps.
Industry News
April 18, 2024
Red Hat announced updates to Red Hat Trusted Software Supply Chain.
April 18, 2024
Tricentis announced the latest update to the company’s AI offerings with the launch of Tricentis Copilot, a suite of solutions leveraging generative AI to enhance productivity throughout the entire testing lifecycle.
April 17, 2024
CIQ launched fully supported, upstream stable kernels for Rocky Linux via the CIQ Enterprise Linux Platform, providing enhanced performance, hardware compatibility and security.
April 17, 2024
Redgate launched an enterprise version of its database monitoring tool, providing a range of new features to address the challenges of scale and complexity faced by larger organizations.
April 17, 2024
Snyk announced the expansion of its current partnership with Google Cloud to advance secure code generated by Google Cloud’s generative-AI-powered collaborator service, Gemini Code Assist.
April 16, 2024
Kong announced the commercial availability of Kong Konnect Dedicated Cloud Gateways on Amazon Web Services (AWS).
April 16, 2024
Pegasystems announced the general availability of Pega Infinity ’24.1™.
April 16, 2024
Sylabs announces the launch of a new certification focusing on the Singularity container platform.
April 15, 2024
OpenText™ announced Cloud Editions (CE) 24.2, including OpenText DevOps Cloud and OpenText™ DevOps Aviator.
April 15, 2024
Postman announced its acquisition of Orbit, the community growth platform for developer companies.
April 11, 2024
Check Point® Software Technologies Ltd. announced new email security features that enhance its Check Point Harmony Email & Collaboration portfolio: Patented unified quarantine, DMARC monitoring, archiving, and Smart Banners.
April 11, 2024
Automation Anywhere announced an expanded partnership with Google Cloud to leverage the combined power of generative AI and its own specialized, generative AI automation models to give companies a powerful solution to optimize and transform their business.
April 11, 2024
Jetic announced the release of Jetlets, a low-code and no-code block template, that allows users to easily build any technically advanced integration use case, typically not covered by alternative integration platforms.
April 10, 2024
Progress announced new powerful capabilities and enhancements in the latest release of Progress® Sitefinity®.

