
SmartBear announced a new version of its API design and documentation tool, SwaggerHub, integrating Stoplight’s API open source tools.
Automated Sensitive Data Leak Detection
May 14, 2020
The average multinational spends several million dollars a year on compliance, while in highly regulated industries — like financial services and defense — the costs can be in the tens or even hundreds of millions. Despite conducting these rigorous assessments yet we wake up to data breach announcements on an hourly basis.
If you’ve been following the trends around modern application development, you’ve likely been inundated with reasons why you need to adopt microservices. Writing software in this manner places the application as the source of essential complexity, resulting in the accidental complexity of the application’s data model, a common side effect of software development.
Employees, too, often resent compliance programs, seeing them as a series of box-checking routines and time-consuming exercises. In our view, all this expense and frustration is tragic — and avoidable. The answer, we believe, lies in better measurement.
Governance standards and guidance for secure programming call for sensitive data to be redacted/obfuscated in applications prior to being persisted, operated upon and dispatched on secure communication channels.
An attacker might be able to observe or provoke a system into “leaking” or revealing secret data, such as cryptographic keys, the plaintext of passwords and so on. A well-documented example is where an intruder manages to read the operating system page file or a core dump of a running (or deliberately terminated) process in order to gain access to sensitive data.
Several coding standards and guidance documents exist that call for sensitive data to be redacted when dispatched to a logging provider or third party value-added SaaS services but offer little advice on how this is to be achieved or verified, especially given the complexity of programming languages and hardware.
Why is Tracking Sensitive Data a Hard Problem?
Redacting sensitive data might seem simple at first: just overwrite the most or least significant bits of data with zeros or XXXs and carry on, right? A less trivial analysis reveals important questions, including:
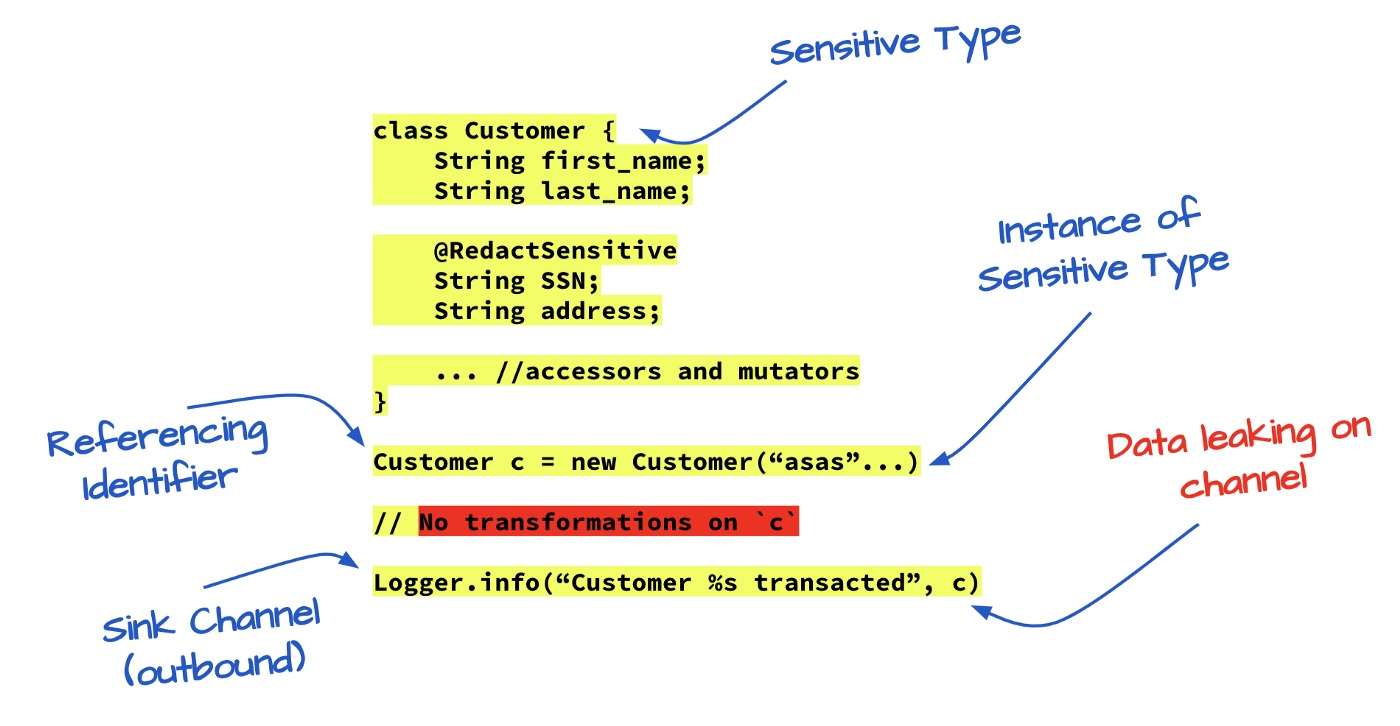
■ How do we define “sensitive”? What objects in the program are “sensitive” and how are they identified?
■ Imagine that we have two variables X and Y which are defined to be “sensitive.” We then declare and initialize another local variable Z with an initial value derived from some function that combines X and Y.
■ Is Z “sensitive”? Does Z need to be redacted/obfuscated?
■ Exactly when should redaction/obfuscation be performed, relating to the scope and lifetime of data objects which is, in turn, intricately entwined with a particular programming language’s model (functional, object-oriented) of how data should be organized and (de-)allocated?
■ How can we regulate the flow of sensitive data and its derivatives throughout the scope of the running application? Can sensitive and regulated data be sent to 3rd party analytics services to measure DAUs and MAUs without consent of consumer who owns her/his data?
■ How do we verify that redaction/obfuscation really has been performed correctly, to the satisfaction of ourselves, our customers, and regulators?
The Various Shapes of Data
Data originates when consumers subscribe to interact with value-added services. When a consumer registers or signs in to the service, data objects are created to represent the customer persona. The lifetime of these objects is restricted to the scope of the customer session. A typical customer session triggers various functional flows to serve his or her needs, leading to the creation of many communication paths, both within the core application and across its boundary to other SaaS applications.
Within the scope of these flows, data elements are initialized, referenced, copied, transformed, persisted, sent to other SaaS channels and eventually de-scoped.
First and foremost, it is important to classify these data elements based on degrees of sensitivity. Thereafter, the data element in focus must be observed in the context of its participation in flows, both within and outside the boundaries of the application.
There is no “sensitive” control-switch to alleviate such concerns, or if there is it requires onerous researching to enable the precise option. With the lack of accessible solutions, operations staff deploying cloud-based services can only harden the host surface (with trust-some or trust-none policies), passively sniff for patterns produced by actions in applications and define escalation workflows.
For an instrument to be effective, it would need to
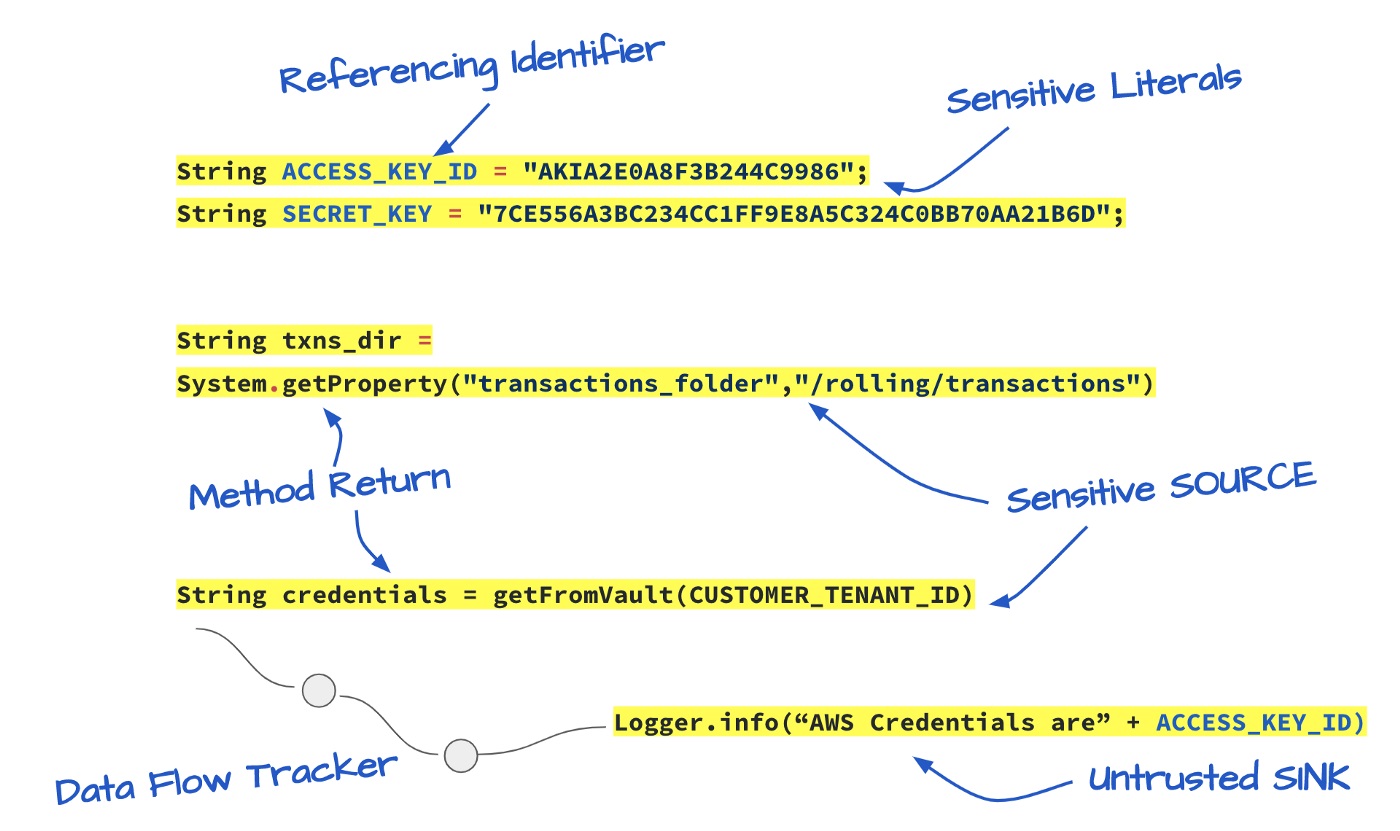
■ have the ability to detect different types of data elements (user-defined types, primitive types, the lineage of data transforms, hardcoded literates, annotated types, referencing identifier to environment data, etc).
■ have the ability to classify these detected types as sensitive based on a supervised model using natural language processing that is trained upon a corpus of compliance mandates.
■ track all transformations, lineage, and provenance of such sensitive types.
■ finally measure if such sensitive types are violating any current (SOC-2, GDPR) or forthcoming (CCPA) compliance constraints.
Prevent Compliance Metrics from Going Astray
So how do we create models that can credibly evaluate the impact of a data-driven compliance program?
Let’s start by understanding Data and Behavior — What the Application Knows and What It Can Do.
In all programming paradigms, there are two primary components: the data (what an application knows) and behavior (what the application can do with that data, such as create, read, update, delete, transform, etc.). Object-oriented programming says that combining data and behavior in a single location (called an “object”) makes it easier to understand how a program works. Functional programming says that data and behavior are distinctively different and should be kept separate for clarity.
We model communication with the outside world via interfaces. An interface is an abstraction that describes a device that is used to exchange data with a communication partner. Interfaces may be network connections, files or other programs reachable via IPC/RPC mechanisms. In this regard, an interface is similar to the UNIX concept of a file. We assume that each interface is represented as an object in the code, for example, a file-descriptor variable or a variable representing an input/output stream. We refer to this variable as the interface descriptor (analogous to the UNIX file descriptor).
Thereafter the system should be able to identify the following operations on interfaces:
■ Read operations — A program obtaining information from the outside world by invoking a read library function to which the interface descriptor is passed.
■ Write operations — The termination point (or endpoint) of an ordered data flow.
■ Transformations — In addition to read and write interface interactions, we identify data transformations, for example, encryption/decryption, redaction, escape routines, etc.
Taking a code-as-data approach we should be able to deterministically quantify both data and behavior in a binding context.
Industry News
April 18, 2024
Red Hat announced updates to Red Hat Trusted Software Supply Chain.
April 18, 2024
Tricentis announced the latest update to the company’s AI offerings with the launch of Tricentis Copilot, a suite of solutions leveraging generative AI to enhance productivity throughout the entire testing lifecycle.
April 17, 2024
CIQ launched fully supported, upstream stable kernels for Rocky Linux via the CIQ Enterprise Linux Platform, providing enhanced performance, hardware compatibility and security.
April 17, 2024
Redgate launched an enterprise version of its database monitoring tool, providing a range of new features to address the challenges of scale and complexity faced by larger organizations.
April 17, 2024
Snyk announced the expansion of its current partnership with Google Cloud to advance secure code generated by Google Cloud’s generative-AI-powered collaborator service, Gemini Code Assist.
April 16, 2024
Kong announced the commercial availability of Kong Konnect Dedicated Cloud Gateways on Amazon Web Services (AWS).
April 16, 2024
Pegasystems announced the general availability of Pega Infinity ’24.1™.
April 16, 2024
Sylabs announces the launch of a new certification focusing on the Singularity container platform.
April 15, 2024
OpenText™ announced Cloud Editions (CE) 24.2, including OpenText DevOps Cloud and OpenText™ DevOps Aviator.
April 15, 2024
Postman announced its acquisition of Orbit, the community growth platform for developer companies.
April 11, 2024
Check Point® Software Technologies Ltd. announced new email security features that enhance its Check Point Harmony Email & Collaboration portfolio: Patented unified quarantine, DMARC monitoring, archiving, and Smart Banners.
April 11, 2024
Automation Anywhere announced an expanded partnership with Google Cloud to leverage the combined power of generative AI and its own specialized, generative AI automation models to give companies a powerful solution to optimize and transform their business.
April 11, 2024
Jetic announced the release of Jetlets, a low-code and no-code block template, that allows users to easily build any technically advanced integration use case, typically not covered by alternative integration platforms.
April 10, 2024
Progress announced new powerful capabilities and enhancements in the latest release of Progress® Sitefinity®.

